
Building an End-to-End Machine Learning Pipeline for Prediction
Project GoalClient or Institution: Internal / Random Project
Project Goal: Develop an end-to-end machine learning pipeline covering ingestion, preprocessing, modeling, evaluation, and deployment, wrapped in a user-friendly web app with Azure CI/CD integration
Tools Used: Python, Scikit-learn, Flask, Azure Web Apps, GitHub Actions, Visual Studio Code
Duration: 1 month
Outcome: Fully reproducible regression/classification framework deployed as a cloud-based web app
Link: GitHub Repository
Deploying Scalable, Reproducible ML Pipelines with CI/CD and Azure Integration
Abstract
This project demonstrates how to transform a local machine learning pipeline into a full-fledged web application ready for public use. I built a modular, reproducible machine learning workflow for tabular data, supporting both classification and regression tasks. The pipeline was integrated with a Flask-based web interface and deployed to Azure using GitHub Actions for seamless CI/CD. This work showcases the feasibility of creating accessible and scalable ML apps with minimal infrastructure.
🧠 Background & Problem Statement
Many machine learning tutorials stop at model evaluation. But real-world use cases demand deployment, user interfaces, and automation. This project tackles that gap by offering a full-stack approach—from data ingestion to prediction, all within a framework that users can interact with via a browser.
By enabling online predictions through a custom form and auto-deployment via GitHub Actions to Microsoft Azure, the project bridges the divide between ML engineering and user accessibility.
Dataset
- Primary Dataset: Heart Disease Dataset for classification
- Other Datasets: Any structured/tabular dataset (CSV) can be applied
- Preprocessing:
- Null handling
- Encoding of categorical variables
- Feature scaling using
StandardScaler - Train-test split via
train_test_split
Approach & Methodology
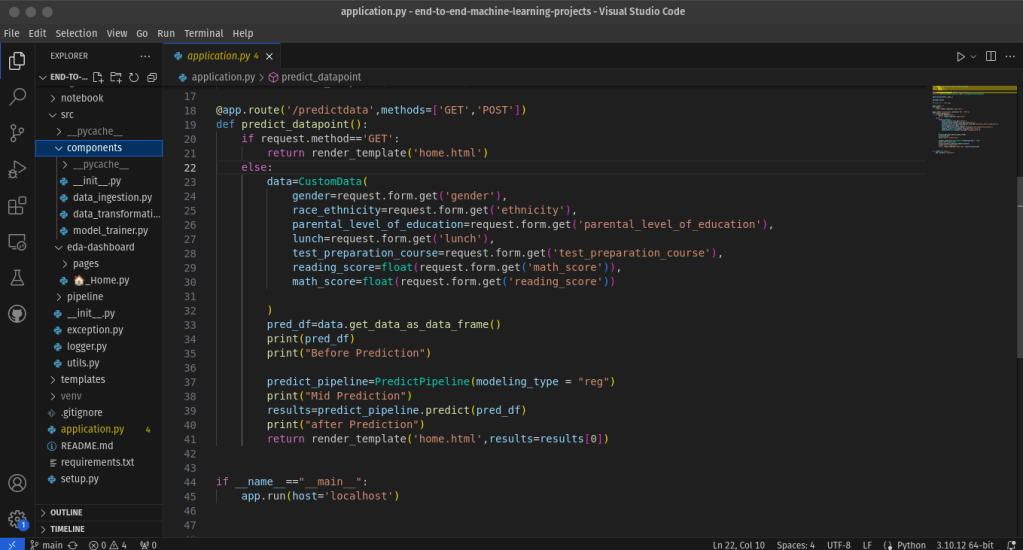
🔹 1. Modular Codebase
- Structured the code into reusable modules:
data_ingestion.pydata_transformation.pymodel_trainer.pyutils.pypredict_datapoint.py
🔹 2. Model Training
- Trained models for both classification and regression using:
LogisticRegression,RandomForest, XGBoost,LinearRegression, etc.
- Metrics used:
accuracy, F1-score,mean squared error, andr2_score, etc.
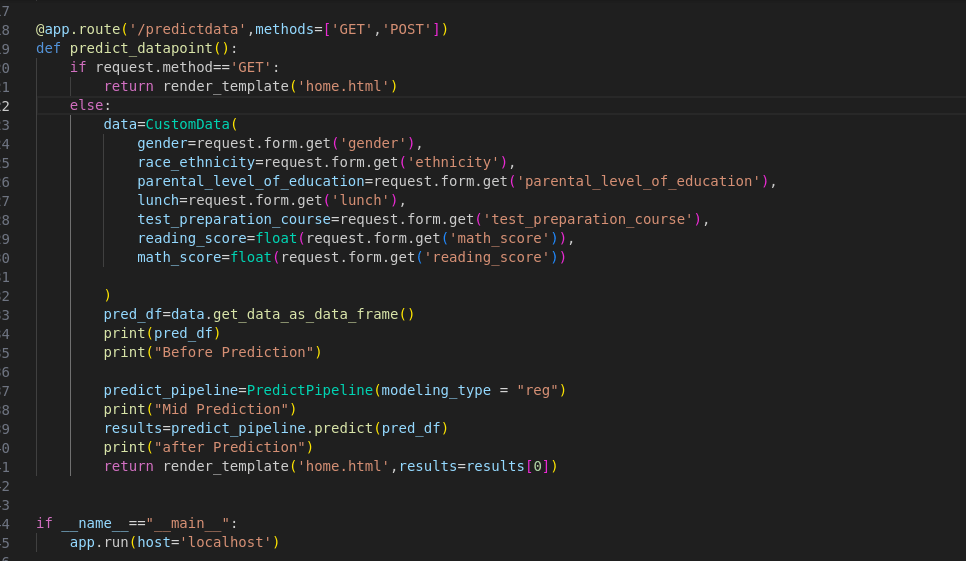
🔹 3. Flask Web App
- Built a front-end form with inputs for features like gender, education level, scores, etc.
- Upon submission, a prediction is made using the trained pipeline and returned to the user.
🔹 4. CI/CD Pipeline
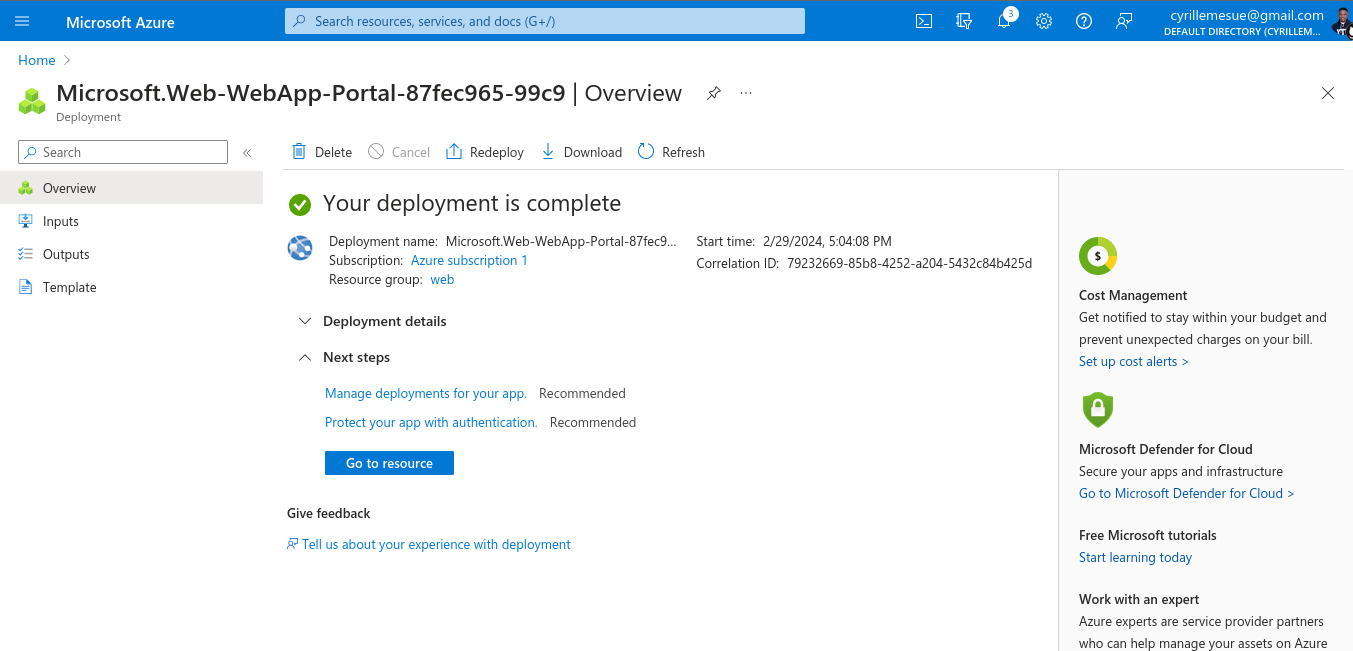
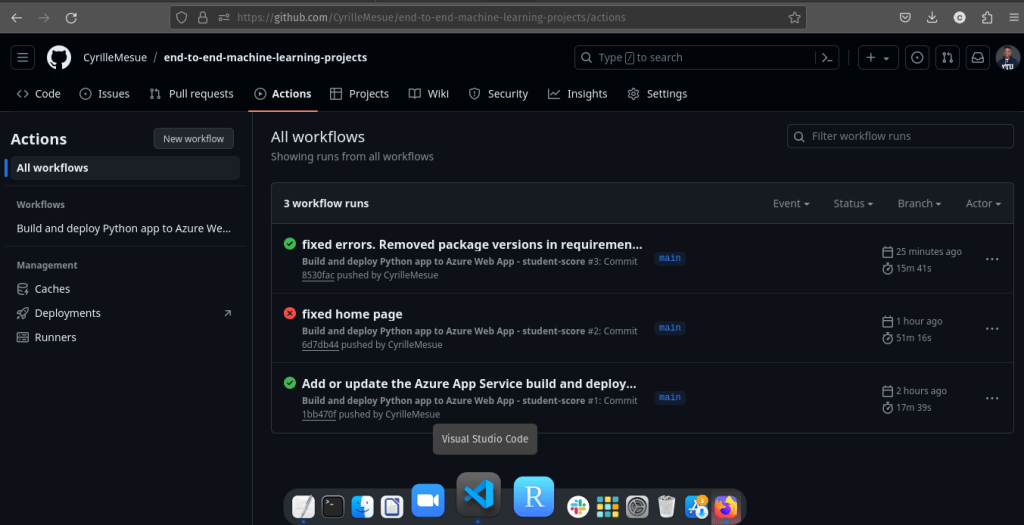
- GitHub Actions: Configured a YAML workflow to deploy app changes to Azure automatically on every push
- Azure Web App Service: Hosted the live app with secure and scalable access
📈 Key Results
- ✅ Reproducible and modular ML pipeline supporting classification and regression
- 🌐 Fully deployed Flask application for public prediction tasks
- 🔁 Continuous deployment via GitHub Actions
- 📊 Accurate predictions on unseen data (e.g., “Your predicted writing score is 54.75”)
💡 Lessons Learned / Innovations
- Developing a complete pipeline taught me the importance of designing for modularity and reproducibility
- Debugging CI/CD pipelines with GitHub Actions gave me deeper insight into DevOps practices
- Learned to handle Azure deployment configs, requirements packaging, and Python versioning
Challenge:
Hosting on AWS was avoided due to paid-only options. Azure Web App provided a suitable free-tier alternative.
💬 Discussion
This project showcases the feasibility of integrating data science and software engineering into a single workflow. It’s a model that can be applied to clinical predictors, business dashboards, or academic tools. The plug-and-play nature of the code makes it easy to swap datasets or models for different use cases.
Whether it’s a heart disease classifier or a student performance predictor, the backend stays intact—only inputs and logic change.
📣 Call to Action
This was a personal project built to sharpen my full-stack ML deployment skills. If you’re looking to turn a predictive model into a public-facing tool or automate your ML workflow, start a conversation.
Final Thoughts & Future Directions
In future iterations, I aim to:
- Integrate Docker for containerized deployment
- Add API endpoints for programmatic access
- Expand the UI with plot visualizations and multiple model choices
Ultimately, this project demonstrates that any ML model can be production-ready with the right scaffolding.

Leave a comment