
Ensemble Feature Selection for Robust Multi-Omics Biomarker Discovery
- Research Project: Independent Research + Publication
- Project Goal: Develop and benchmark ensemble feature selection strategies for stable and biologically meaningful biomarker discovery across multi-omics datasets
- Tools Used: Python (Scikit-learn, XGBoost, SHAP, LIME), R (glmnet, Boruta, RobustRankAggreg), PyTorch, Pandas, NumPy
- Outcome: Contributed to BioMark, a published biomarker analysis platform (BMC Bioinformatics, 2026), and co-authored a large-scale benchmarking manuscript submitted to Briefings in Bioinformatics
A Systems-Level Approach to Biomarker Discovery
Abstract
Biomarker discovery often suffers from instability — different feature selection algorithms produce different gene lists, reducing reproducibility and clinical trust.
This project addressed that challenge by designing and implementing a comprehensive ensemble feature selection framework that integrates multiple ranking strategies and machine learning classifiers to identify robust biomarkers across heterogeneous omics datasets.
The framework was later integrated into the BioMark user interface platform:
Balikci, M.A., Njume, C.M. & Cakmak, A.
BioMark: biomarker analysis tool.
BMC Bioinformatics 27, 42 (2026).
https://doi.org/10.1186/s12859-025-06346-3
🧠 Problem Statement
Single feature selection methods are:
- Sensitive to noise
- Biased toward model assumptions
- Unstable across datasets
- Often poorly reproducible
Research questions addressed:
- Do ensemble feature selection methods improve stability and predictive performance?
- Which aggregation strategies perform best across multi-omics cohorts?
- Do complex models outperform simpler interpretable classifiers?
- How stable are biomarker panels across diseases?
🛠 Feature Selection Methods Implemented
🔹 Embedded & Regularized Models
- Lasso
- Elastic Net
- Logistic Regression (L1/L2)
- Random Forest importance
- XGBoost importance
🔹 Wrapper Methods
- SVM-RFE
- Boruta
🔹 Statistical Methods
- T-Test
- Fold Change ranking
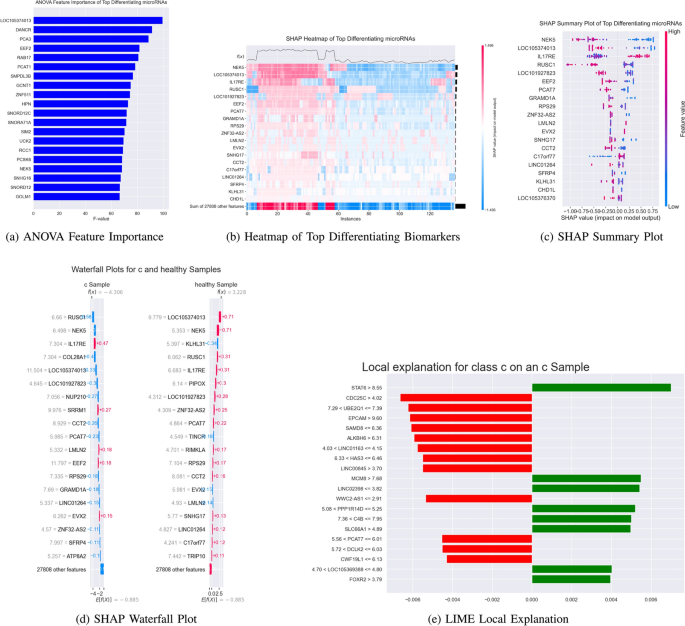
🔹 Explainability-Based Methods
- SHAP (mean absolute importance)
- LIME (local interpretability aggregation)
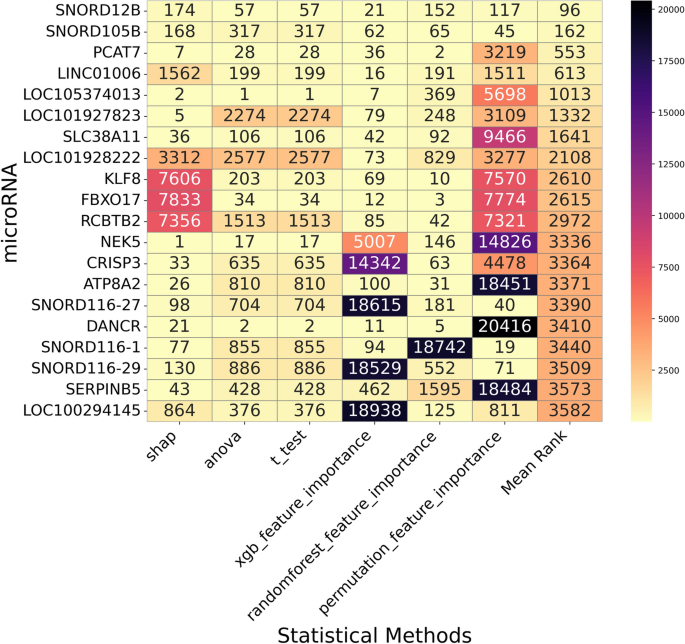
🔗 Ensemble Aggregation Strategies
Two major ensemble paradigms were implemented:
📊 Rank-Based Aggregation
- Min Rank
- Mean Rank
- Median Rank
- Geometric Mean Rank
- Robust Rank Aggregation (RRA)
- Stuart Aggregation
⚖ Weight-Based Aggregation
- Mean Weight
- Max Weight
- Median Weight
- Geometric Mean Weight
- Threshold Algorithm
This allowed systematic comparison between rank-level and importance-level integration strategies.
🤖 Classification Models Evaluated
To evaluate biological relevance and predictive performance, selected biomarker panels were tested using:
- Random Forest
- XGBoost
- Support Vector Classifier (SVC)
- Logistic Regression
- Multi-Layer Perceptron (MLP)
Performance metrics:
- Accuracy
- F1-score
- ROC-AUC
- Stability scores
- Cross-validation consistency
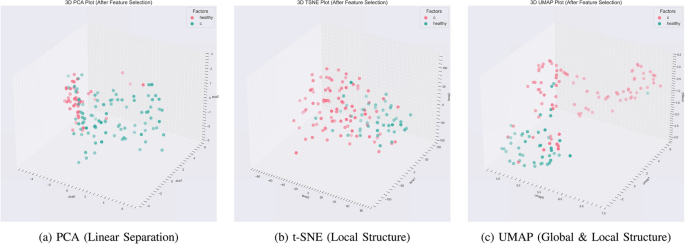
🧬 Multi-Omics Benchmark Study
The framework was evaluated across three independent multi-omics cohorts, including:
- Alzheimer’s disease
- Progressive supranuclear palsy
- Breast cancer
Data types included:
- Transcriptomics
- microRNA
- Metabolomics
- Combined multi-omics
Key finding:
Ensemble feature selection consistently improved robustness and performance compared to single-method selection.
Surprisingly:
Simpler classifiers (Logistic Regression, SVC) often matched or outperformed deeper models, particularly when combined with ensemble feature selection.
This work formed the basis of a large-scale benchmarking manuscript currently submitted to Briefings in Bioinformatics.
💻 Engineering Contributions
I implemented:
- Modular ranking pipelines
- Automated ensemble aggregation modules
- Cross-validation benchmarking framework
- Stability analysis metrics
- End-to-end evaluation pipelines
- Integration-ready backend architecture
My codebase was later integrated into the BioMark platform, providing researchers with a user-friendly interface to perform advanced biomarker discovery without deep programming knowledge.
📊 Key Insights
- Ensemble selection reduces method-specific bias
- Rank aggregation improves stability more than weight aggregation
- Deep learning did not consistently outperform classical ML
- Triple-omics integration provided the highest validation rates
- Small, well-selected biomarker panels can outperform large noisy feature sets
📣 Impact
This work contributed to:
- A published software platform (BioMark)
- A large-scale benchmarking manuscript
- Reproducible, modular biomarker discovery pipelines
- Practical guidance for researchers working with multi-omics data
🚀 Interested in Robust Biomarker Discovery?
If you’re working with:
- Multi-omics datasets
- Disease classification tasks
- Translational biomarker research
- Feature instability problems
I can help design and benchmark reproducible, ensemble-based biomarker pipelines tailored to your dataset.



Leave a comment